...
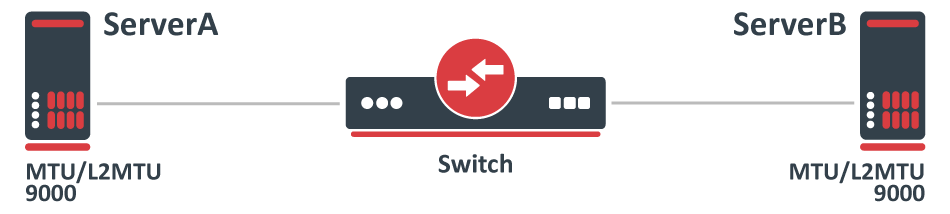
Consider the following scenario, you have multiple devices in your network, most of them are used as a switch/bridge in your network and there are certain endpoints that are supposed to receive and process traffic. To decrease the overhead in your network, you have decided to increase the MTU size so you set a larger MTU size on both endpoints, but you start to notice that some packets are being dropped.

Configuration
In this case, both endpoints can be any type of device, we will assume that they are both Linux servers that are supposed to transfer a large amount of data. In such a scenario you would have probably set something similar to this on ServerA and ServerB:
| Code Block |
|---|
ip link set eth1 mtu 9000 |
...
And on your Switch you have probably have set something similar to this:
| Code Block | ||
|---|---|---|
| ||
/interface bridge
add name=bridge1
/interface bridge port
add interface=ether1 bridge=bridge1
add interface=ether2 bridge=bridge1 |
...
Problem
This is a very simplified problem, but in larger networks, this might not be very easy to detect. For instance, ping might be working since a generic ping packet will be 70 bytes long (14 bytes for Ethernet header, 20 bytes for IPv4 header, 8 bytes for ICMP header, 28 bytes for ICMP payload), but data transfer might not work properly. The reason why some packets might not get forwarded is that MikroTik devices running RouterOS by default has MTU set to 1500 and L2MTU set to something around 1580 bytes (depends on the device), but the Ethernet interface will silently drop anything that does not fit into the L2MTU size. Note that the L2MTU parameter is not relevant to x86 or CHR devices. For a device that is only supposed to forward packets, there is no need to increase the MTU size, it is only required to increase the L2MTU size, RouterOS will not allow you to increase the MTU size that is larger than the L2MTU size. If you require the packet to be received on the interface and the device needs to process this packet rather than just forwarding it, for example, in case of routing, then it is required to increase the L2MTU and the MTU size, but you can leave the MTU size on the interface to the default value if you are using only IP traffic (that supports packet fragmentation) and don't mind that packets are being fragmented. You can use the ping utility to make sure that all devices are able to forward jumbo frames:
| Code Block | ||
|---|---|---|
| ||
/ping 192.168.88.1 size=9000 do-not-fragment |
...
Remember that the L2MTU and MTU size needs to be larger or equal to the ping packet size on the device from which and to which you are sending a ping packet , since ping (ICMP) is IP traffic that is sent out from a an interface over Layer3.
Symptoms
...
Increase the L2MTU size on your Switch:
| Code Block | ||
|---|---|---|
| ||
/interface ethernet
set ether1,ether2 l2mtu=9000 |
...
In case your traffic is encapsulated (VLAN, VPN, MPLS, VPLS or other), then you might need to consider setting even a larger L2MTU size. In this scenario, it is not needed to increase the MTU size for the reason described above.Note:
| Note |
|---|
Full frame MTU is not the same as L2MTU. L2MTU size does not include the Ethernet header (14 bytes) and the CRC checksum (FCS) field. The FCS field is stripped by the Ethernet's driver and RouterOS will never show the extra 4 bytes to any packet. For example, if |
...
you set MTU and L2MTU to 9000, then the full-frame MTU is 9014 bytes long, this can also be observed when sniffing packets with " |
Bridge and reserved MAC addresses
...
For both devices DeviceA and DeviceB there should be a very similar configuration.
| Code Block | ||
|---|---|---|
| ||
/interface bridge
add name=bridge1 protocol-mode=rstp
/interface bridge port
add interface=ether1 bridge=bridge1
add interface=eoip1 bridge=bridge1 |
...
Problem
Both devices are able to communicate with each other, but some protocols do not work properly. The reason is that as soon as you use any STP variant (STP, RSTP, MSTP), you make the bridge compliant with IEEE 802.1D and IEEE 802.1Q, these standards recommend that packets that are destined to 01:80:C2:XX:XX:XX should NOT be forwarded. In cases where there are only 2 ports added to a bridge (R/M)STP should not be used since a loop cannot occur from 2 interfaces and if a loop does occur, the cause is elsewhere and should be fixed on a different bridge. Since (R/M)STP is not needed in transparent bridge setups, it can be disabled. As soon as (R/M)STP is disabled, the RouterOS bridge is not compliant with IEEE 802.1D and IEEE 802.1Q and therefore will forward packets that are destined to 01:80:C2:XX:XX:XX.
...
Since RouterOS v6.43 it is possible to partly disable compliance with IEEE 802.1D and IEEE 802.1Q, this can be done by changing the bridge protocol mode.
| Code Block | ||
|---|---|---|
| ||
/interface bridge
set bridge1 protocol-mode=none |
...
| Warning |
|---|
...
The IEEE 802.1x standard is meant to be used between a switch and a client directly. If it is possible to connect a device between the switch and the client, then this creates a security threat. For this reason, it is not recommended to disable the compliance with IEEE 802.1D and IEEE 802.1Q, but rather design a proper network topology. |
Bonding between Wireless links
Consider the following scenario, you have set up multiple Wireless links and to achieve maximum throughput and yet to achieve redundancy you have decided to place Ethernet interfaces into a bond and depending on the traffic that is being forwarded you have chosen a certain bonding mode. This scenario can be applied to any case, where a bonding interface is created between links, that are not directly connected to each other.
 Bonding with Wireless links setup
Bonding with Wireless links setup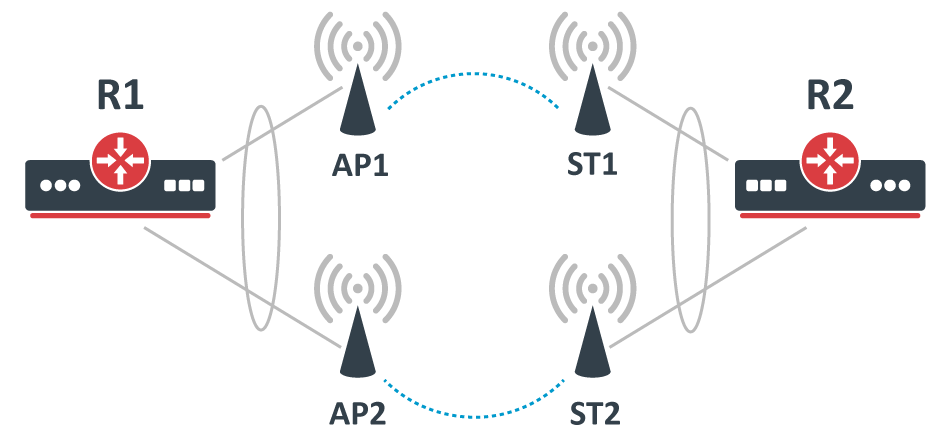
Configuration
The following configuration is relevant to R1 and R2:
| Code Block | ||
|---|---|---|
| ||
/interface bonding
add mode=802.3ad name=bond1 slaves=ether1,ether2 transmit-hash-policy=layer-2-and-3
/ip address
add address=192.168.1.X/24 interface=bond1 |
...
While the following configuration is relevant to AP1, AP2, ST1 and ST2:
| Code Block | ||
|---|---|---|
| ||
/interface bridge
add name=bridge1 protocol-mode=none
/interface bridge port
add interface=ether1 bridge=bridge1
add interface=wlan1 bridge=bridge1
/ip address
add address=192.168.1.X/24 interface=bridge1 |
...
Where X corresponds to and an IP address for each device.
...
While traffic is being forwarded properly between R1 and R2, load balancing, link fail-over failover is working properly as well, but devices between R1 and R2 are not not always accessible or some of them are completely inaccessible (in most cases AP2 and ST2 is are inaccessible). After examining the problem you might notice that packets do not always get forwarded over the required bonding slave and as a result, never is received by the device you are trying to access. This is a network design and bonding protocol limitation. As soon as a packet needs to be sent out through a bonding interface (in this case you might be trying to send ICMP packets to AP2 or ST2), the bonding interface will create a hash based on the selected bonding mode and transmit-hash-policy and will select an interface, through which to send the packet out, regardless if the destination is only reachable only through a certain interface. Some devices will be accessible because the generated hash matches the interface, on which the device is located on, but it might not choose the needed interface as well, which will result in inaccessible device. Only broadcast bonding mode does not have this kind of protocol limitation, but this bonding mode has a very limited use case.
...
Bonding interfaces are not supposed to be connected using in-direct links, but it is still possible to create a workaround. The idea behind this workaround is to find a way to bypass packets being sent out using the bonding interface. There are multiple ways to force a packet not to be sent out using the bonding interface, but essentially the solution is to create new interfaces on top of physical interfaces and add these newly created interfaces to a bond instead of the physical interfaces. One way to achieve this is to create EoIP tunnels on each physical interface, but that creates a huge overhead and will reduce overall throughput. You should create a VLAN interface on top of each physical interface instead, this creates a much smaller overhead and will not impact overall performance noticeably. Here is an example how R1 and R2 should be reconfigured:
| Code Block | ||
|---|---|---|
| ||
/interface vlan
add interface=ether1 name=VLAN_ether1 vlan-id=999
add interface=ether2 name=VLAN_ether2 vlan-id=999
/interface bonding
add mode=balance-xor name=bond1 slaves=VLAN_ether1,VLAN_ether2 transmit-hash-policy=layer-2-and-3
/ip address
add address=192.168.1.X/24 interface=bond1
add address=192.168.11.X/24 interface=ether1
add address=192.168.22.X/24 interface=ether2 |
...
AP1 and ST1 only needs updated IP addresses to the correct subnet:
| Code Block |
|---|
/ip address
add address=192.168.11.X/24 interface=bridge1 |
...
Same changes must be applied to AP2 and ST2 (make sure to use the correct subnet):
| Code Block | ||
|---|---|---|
| ||
/ip address
add address=192.168.22.X/24 interface=bridge1 |
...
With this approach, you create the least overhead and the least configuration changes are required.
| Note |
|---|
...
LACP (802.3ad) is not mean to be used in setups, where devices bonding slaves are not directly connected, in this case, it is not recommended to use LACP, if there are Wireless links between both routers. LACP requires both bonding slaves to be at the same link speeds, Wireless links can change its rates at any time, which will decrease overall performance and stability. Other bonding modes should be used instead. |
Bandwidth testing
Consider the following scenario, you set up a link between two devices, this can be any link, an Ethernet cable, a Wireless wireless link, a tunnel or any other connection. You decide that you want to test the link's bandwidth, but for convenience reasons, you decide to start testing the link with the same devices that are running the link.
 Bad way to test bandwidth or throughput
Bad way to test bandwidth or throughput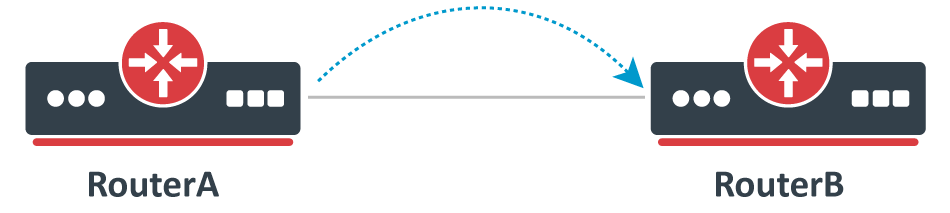
Problem
As soon as you start Bandwidth test or Traffic generator you notice that the throughput is much smaller than expected. For very powerful routers, which should be able to forward many Gigabits per second (Gbps) you notice that only a few Gigabits per second gets forwarded. The reason why this is happening is because of the testing method you are using, you should never test throughput on a router while using the same router for generating traffic , this is especially true when using Bandwidth test since it is only able to generate traffic on a single CPU core and also applies when using Traffic-generator, though it can run on multiple cores, but you are still adding a because you are adding an additional load on the CPU that reduces the total throughput.
...
- Low throughput
- High CPU usage on one CPU core
Solution
Use a proper testing method. Don't use Bandwidth-test to test large capacity links and don't run any tool that generates traffic on the same device you are testing. Design your network properly so you can attach devices that will generate and receive traffic on both ends. If you are familiar with Iperf, then this concept should be clear. Remember that in real world a router or a switch does not generate large amounts of traffic (at least it shouldn't, otherwise, it might indicate an existing security issue), a server/client generates the traffic while a router/switch forwards the traffic (and does some manipulations to the traffic in appropriate cases).
 Proper way to test bandwidth or throughput
Proper way to test bandwidth or throughput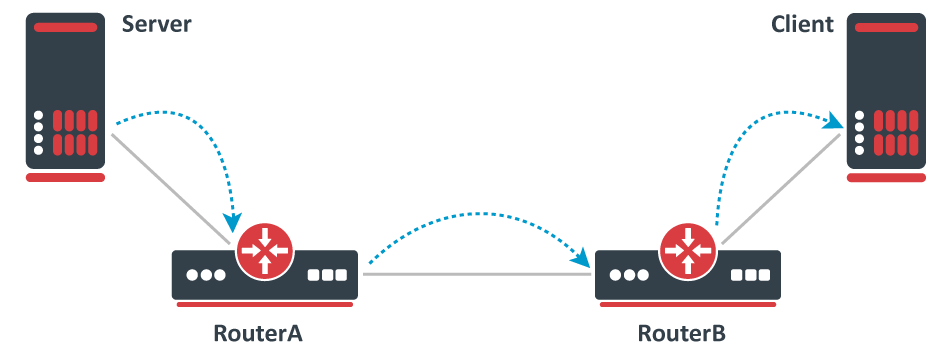
Bridge split-horizon usage
Consider the following scenario, you have a bridge and you need to isolate certain bridge ports from each other. There are options to use a built-in switch chip to isolate certain ports on certain switch chips, you can use bridge firewall rules to prevent certain ports to be able to send any traffic to other ports, you can isolate ports in a PVLAN type of setup using port isolation, but there is also a software-based solution to use bridge split-horizon (which disables hardware offloading on all switch chips).
Configuration
| Code Block | ||
|---|---|---|
| ||
/interface bridge
add name=bridge1
/interface bridge port
add bridge=bridge1 horizon=1 hw=no interface=ether1
add bridge=bridge1 horizon=2 hw=no interface=ether2
add bridge=bridge1 horizon=3 hw=no interface=ether3
add bridge=bridge1 horizon=4 hw=no interface=ether4 |
...
Problem
After setting the bridge split-horizon on each port, you start to notice that each port is still able to send data between each other. The reason for this is the misuse of bridge split-horizon. A bridge port is only not able to communicate with ports that are in the same horizon, for example, horizon=1 is not able to communicate with horizon=1, but is able to communicate with horizon=2, horizon=3 and so on.
...
Set a proper value as the bridge split-horizon. In case you want to isolate each port from each other (a common scenario for PPPoE setups) and each port is only able to communicate with the bridge itself, then all ports must be in the same bridge split-horizon.
| Code Block | ||
|---|---|---|
| ||
/interface bridge port
set [f] horizon=1 |
...
| Note |
|---|
...
Setting all bridge ports in the same bridge split-horizon will result in traffic being only able to reach the bridge interface itself, then packets can only be routed. This is useful when you want other devices to filter out certain traffic. Similar behavior can be achieved using bridge filter rules. |
Unsupported SFP modules
Consider the following scenario, you have decided to use optical fibre fiber cables to connect your devices together by using SFP or SFP+ optical modules, but for convenience reasons, you have decided to use SFP optical modules that were available.
...
As soon as you configure your devices to have connectivity on the ports that are using these SFP optical modules, you might notice that either the link is working properly or are experiencing random connectivity issues. There are many vendors that manufacture SFP optical modules, but not all vendors strictly follow SFP MSA, SFF and IEEE 802.3 standards, which can lead to unpredictable compatibility issues, which is a very common issue when using not well known or unsupported SFP optical modules in MikroTik devices.
...
- SFP interface does not link up
- Random packet drop
- Unstable link (flapping)
- SFP module not running after a reboot
- SFP module not running after power-cycle
- SFP module running only on one side
...
You should only use supported SFP modules. Always check the SFP compatibility table if you are intending to use SFP modules manufactured by MikroTik. There are other SFP modules that do work with MikroTik devices as well, check Supported peripherals table to find other SFP modules that have been confirmed to work with MikroTik devices. Some unsupported modules might not be working properly in at certain speeds and with auto-negotiation, you might want to try to disable it and manually set a link speed.